Reinforcement learning (RL) example w/RLMolecule and Ray (5:47)
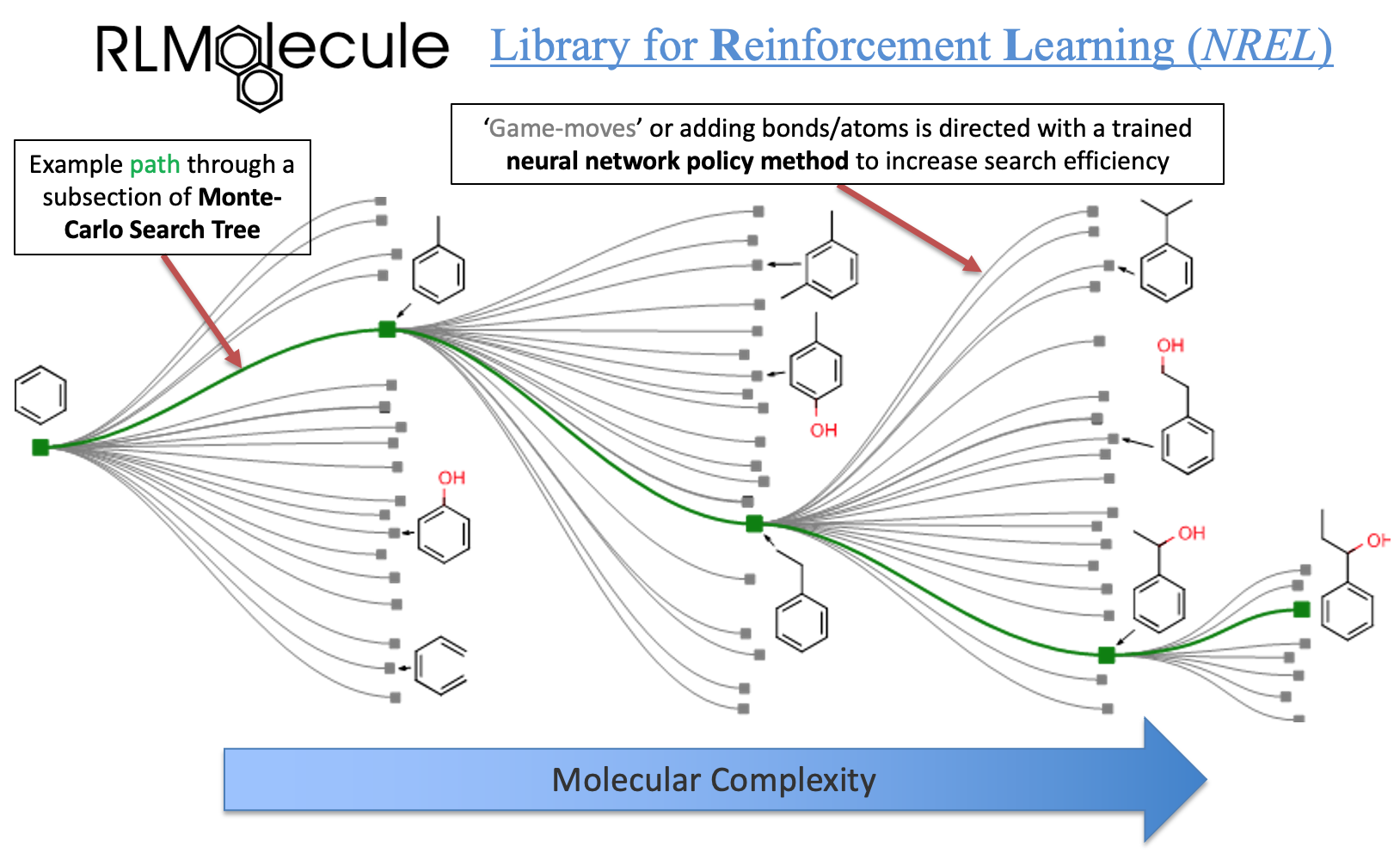
The goal of the rlmolecule library is to enable general-purpose material and molecular optimization using reinforcement learning. It explores the molecular space by adding one atom/bond at a time, learning how to make molecules with desired properties. The notebook makes running your own molecular optimization easy and accessible. Parameter description tables are shown below.
Full 1080p HD resolution and full-screen available through menu on the bottom right of the video
Option |
Description |
|---|---|
Starting molecule |
Starting point for each molecule building episode |
atom additions |
Atom types to choose from when building molecules |
max-atoms |
Maximum number of heavy atoms |
max-#-actions |
Maximum number of actions to allow when building molecules |
SA threshold |
Potential molecules with a Synthetic Accessibility (SA) |
Output isomeric smiles |
Option to not include information about stereochemistry in |
Stereoisomers |
Option to consider stereoisomers as different molecules. |
Canonicalize tautomers |
Option to use RDKit’s tautomer canonicalization functionality. |
3D embedding |
Try to get a 3D embedding of the molecule, and if this fails |
Cache |
Option to cache molecule building for a given SMILES input |
GDB filter |
Option to apply filters from the gdb17 paper to get more |
Hyperparameter |
Good default value |
Range of good values |
Description |
|---|---|---|---|
Training parameters |
|||
gamma |
1 |
0.8 - 1.0 |
Float specifying the discount factor for future rewards i.e., of the Markov |
lr |
0.001 |
0.0001, 0.001, 0.01 |
Learning rate corresponds to the strength of each gradient descent update step. |
entropy_coeff |
0.001 |
0, 0.001, 0.005, 0.01 |
Coefficient of the entropy regularizer. A policy has maximum entropy when all policies |
clip_param |
0.2 |
0.1,0.2,0.3 |
Hyperparameter for clipping in the policy objective. Roughly: how far can the new policy |
kl_coeff |
0 |
0.0 - 1.0 |
Initial coefficient for KL divergence. Penalizes KL-divergence of the old policy vs the |
sgd_minibatch_size |
10 |
10 - 256 |
SGD: Stochastic Gradient DescentTotal batch size across all devices for SGD. |
num_sgd_iter |
5 |
3 - 30 |
Number of SGD iterations in each outer loop (i.e., number of epochs to execute |
train_batch_size |
1000 |
100 - 5000 |
Training batch size. Each train iteration samples the environment for |
GNN policy model |
|||
features |
64 |
32,64,128,256 |
Width of message passing layers |
num_messages |
3 |
1 - 12 |
Number of messages to use in the Graph Neural Network |
RL Run Paramters |
|||
iterations |
10 |
2-1000 |
During each iteration, a certain number of “episodes” are run. Each episode is building |
#-of-rollout workers |
1 |
N/A |
Number of CPU threads available for rollout workers. Workflow will show maximum of threads |